The era of generic "chatbot" evaluation is ending. Professionals don't just need a model that can chat; they need one that can think like an expert in their specific field.
Today, in collaboration with EVJA—a global leader in agronomic intelligence—we are thrilled to announce the release of a groundbreaking new AutoBench run focused entirely on Agronomy.
 More details for this benchmark, including score, cost, and latency data, in the official Hugging Face AutoBench Leaderboard.
More details for this benchmark, including score, cost, and latency data, in the official Hugging Face AutoBench Leaderboard.
Released simultaneously with EVJA’s new Agronomic Intelligence Platform, this benchmark is designed to guide the use of LLMs by professionals in the agricultural sector, testing models on everything from crop disease pathology and soil chemistry to farm logistics and carbon footprint analysis.
This is the first vertical corporate domain-specific LLM benchmark that we make public, a testament to the exceptioonal flexibility of AutoBench in scoring LLM performance in any domain.
- Is there a specific domanin or usecase that are relevant to your business? AutoBench can help you understand what's the best LLM for you, not just in performance but also in cost and latency. Reach out to know more: http://autobench.org *
🤝 Powered by Domain Expertise: The EVJA Partnership
General-purpose AI developers cannot effectively judge specialized agricultural knowledge alone. To ensure this benchmark reflects the real-world needs of the industry, we partnered with EVJA.
Based in Naples and Wageningen (the "Food Valley" of the Netherlands), EVJA has been a pioneer in using sensors and predictive models to optimize crop management since 2015. Their team provided the technical and agronomic support necessary to design the test cases, ensuring that our "judge" models were evaluating data that matters to actual farmers and agronomists.
"Many agritech companies boast about AI solutions, but applications have been limited until now. Our new platform puts AI at the center of agronomic operations," says Davide Parisi, CEO of EVJA. "This benchmark is the natural extension of that vision, helping the industry navigate the complex landscape of LLMs."
Explore the benchmark details in the AutoBench Leaderboard.
🚜 The Scale: Our Biggest Run Yet
To tackle the complexity of modern agriculture, we pushed AutoBench to new limits. This Agronomy run represents our most comprehensive evaluation to date:
- 40 Models Evaluated: The highest number ever on an AutoBench run.
- 20 Ranker Models: A diverse "jury" ensuring unbiased consensus.
- Simulated Real-World Complexity: Over 200 generated questions leading to 8,000 unique responses.
- Massive Evaluation: A total of 160,000 individual rankings generated by our Collective-LLM-as-a-Judge system.
👩🌾 The Methodology: The 4 Agronomic Personas
Agriculture isn't a monolith. With EVJA's guidance, we structured the benchmark around four distinct professional personas to mirror the diverse users of their new Agronomic Intelligence Platform:
- The Small Farmer: Focused on practical, low-cost, immediate solutions.
- The Professional Farmer: Balancing yield optimization with operational efficiency.
- The Large Farm Operator: Managing complex logistics, macro-economics, and scale.
- The Ag Researcher: Demanding high-level scientific accuracy and data analysis.
🏆 The Headlines
The results are in, and they paint a fascinating picture for the sector.
1. OpenAI Dominates the Field
When it comes to pure reasoning and domain knowledge in the proprietary space, OpenAI remains the one to beat.
- GPT-5 and GPT-5.1 secured the top spots, demonstrating superior handling of complex biological and chemical queries.
- Notably, GPT-5-mini also performed exceptionally well, punching above its weight class.
2. The Open-Source Surprise: Mistral Large 2512
The biggest shock of this run comes from the open-weight world. Mistral Large 2512 has emerged as the top open-source model, performing on par with SOTA (State of the Art) proprietary models from Anthropic and Google (Gemini).
For developers building on-premise ag-tech solutions or privacy-focused applications, Mistral Large 2512 is now the gold standard.
3. The "Smart Shopper" Champions
For high-volume agentic workflows—where cost is as critical as accuracy—we found two exceptional performers that break the price-performance barrier:
- gpt-oss-120b
- Grok 4.1 Fast
These models struck incredible results, delivering SOTA-level performance at costs 2 orders of magnitude lower than the proprietary giants.
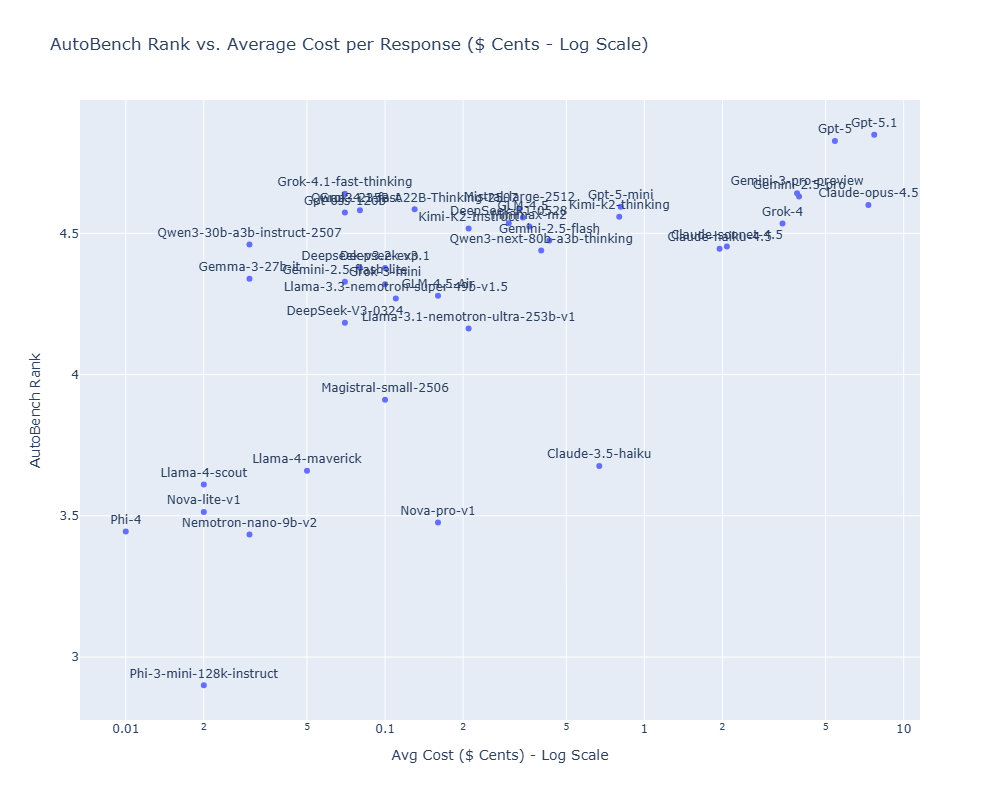
📉 Transparency and Validation
The diffusion of LLMs now involves every sector. More and more companies and professionals in agriculture are adopting AI for multiple activities, from drafting documents to data analysis and agronomic consulting.
By combining AutoBench's scientifically validated "Collective-LLM-as-a-Judge" methodology (proven to have ~92% accuracy correlation with leading benchmarks such as LMarena and Artificla Analysis Intelligence Index) with EVJA's deep domain authority, we are providing the transparency needed to make those adoptions successful.
🔗 Explore the Data and Learn More
Dive into the interactive leaderboard to filter by model, check the price-performance graphs, and see how your favorite models rank on specific agricultural tasks.
👉 View the AutoBench Agronomy Leaderboard
👉 Contribute to AutoBench opensource Hugging Face resources
👉 Learn more about EVJA's new Agronomic Intelligence Platform
What's Next?
The Agronomic benchmark has set a new baseline. We are now working at using AutoBench also for evaluating "reasoning" and agentic capabilities.
- Explore the data: AutoBench Leaderboard
- Read the docs: AutoBench Methodology
Stay tuned for Run 5!
This article is based on the original published on Hugging Face and represents a major milestone in our journey to transform LLM evaluation.